
I am a Lead Researcher and Team Manager in the vivo BlueImage Lab. Our group is the core algorithm team responsible for advancing the photographic quality in the flagship smartphones with the cutting-edge technologies (3D, AIGC, etc).
I was a Senior Researcher in the Visual Computing Center of Tencent AI Lab between 2021 to 2023.
I was a Postdoctoral Researcher in Stanford University supervised by Prof. Leonidas Guibas between 2019 to 2021.
I obtained my PhD degree in the Computer Science and Technology School of Shandong University at 2019. I was supervised by Prof. Baoquan Chen.
My research focus lies in computational photography and Embodied AI. I have published 40+ papers 
👩🎓🧑🎓 Internship at VIVO. If you are interested in the research internship on computational photography, 3DV and Embodied AI, feel free to drop me an email.
🔥 Tech Transfer
VIVO X200 series: Telephoto enhancement via high-fidelity one-step diffusion
VIVO X300 series:
- Text image (Chinese/English) enhancement via diffusion prior
- Landmark image enhancement via reference-guided diffusion (Press: Xinhua News Agency)
- Lens bokeh distillation via one-step diffusion
📝 Selected Publications
Equal contribution$^\star$
🧑🎨 Computational photography
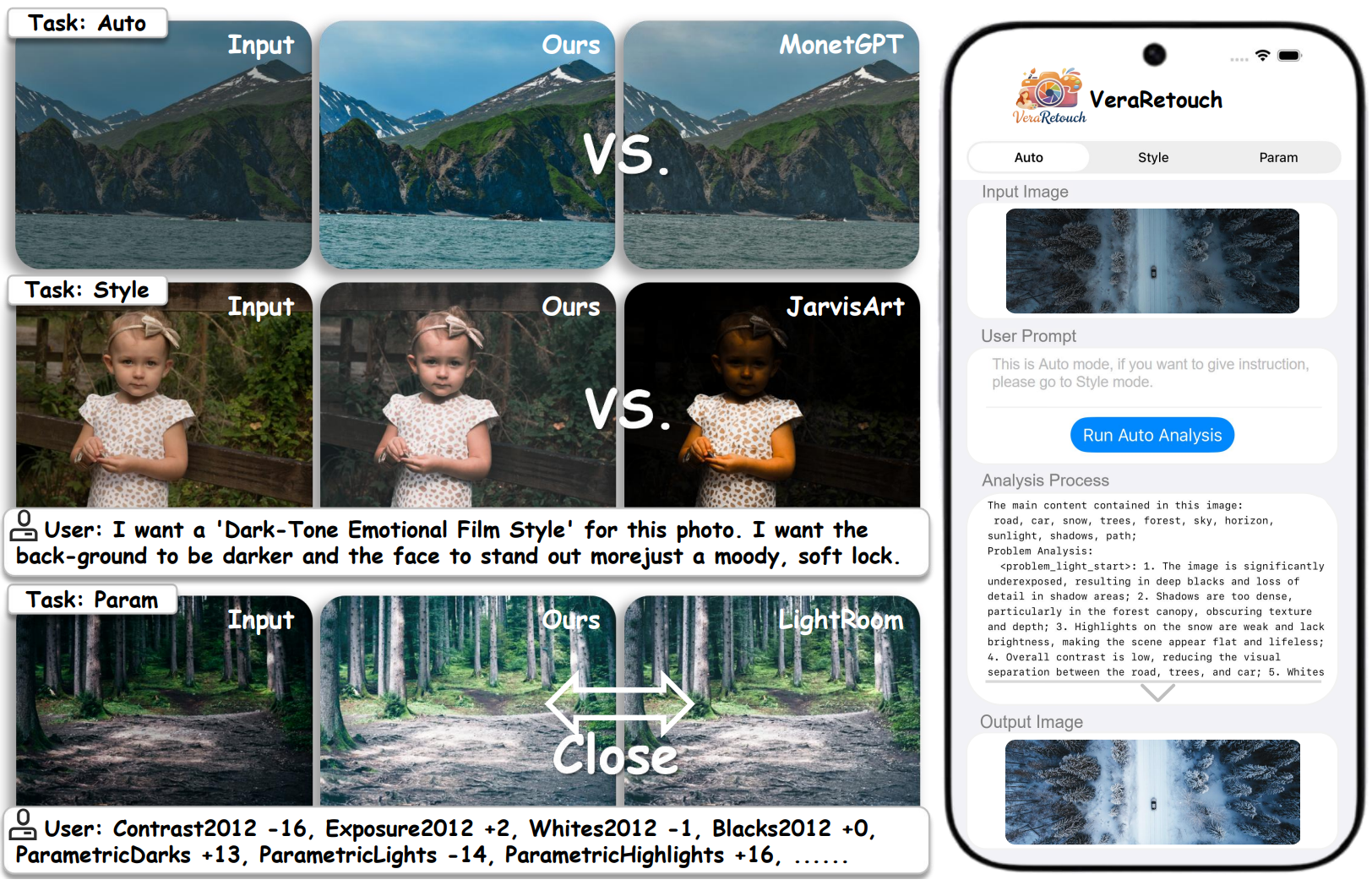
VeraRetouch: A Lightweight Fully Differentiable Framework for Multi-Task Reasoning Photo Retouching
Yihong Guo, Youwei Lyu, Jiajun Tang, Yizhuo Zhou, Hongliang Wang, Jinwei Chen, Changqing Zou, Qingnan Fan.
arXiv / codes / project page
- A research system for automatic, style-driven, and parameterized photo retouching with an interpretable reasoning pipeline and a fully differentiable retouch renderer.
- Real deployment on iPhone 13 Pro Max — no cloud, fully on-device.

LiveMoments: Reselected Key Photo Restoration in Live Photos via Reference-guided Diffusion
Clara Xue*, Zizheng Yan*, Zhenning Shi, Yuhang Yu, Jingyu Zhuang, Qi Zhang, Jinwei Chen, Qingnan Fan.
arXiv / codes / project page
- The first to address the problem of reselected key photo restoration in Live Photos.
- LiveMoments significantly improves perceptual quality and fidelity over existing solutions, including the recent flagships from vivo and iPhone.

BokehDiff: Neural Lens Blur with One-Step Diffusion
Chengxuan Zhu, Qingnan Fan, Qi Zhang, Jinwei Chen, Huaqi Zhang, Chao Xu, Boxin Shi.
arXiv / codes / press: Droider
- The first neural lens blur rendering pipeline based on pretrained diffusion priors.
- A diffusion framework with only one inference step that achieves outstanding quality compared with previous methods, especially in regions where depth prediction fails.
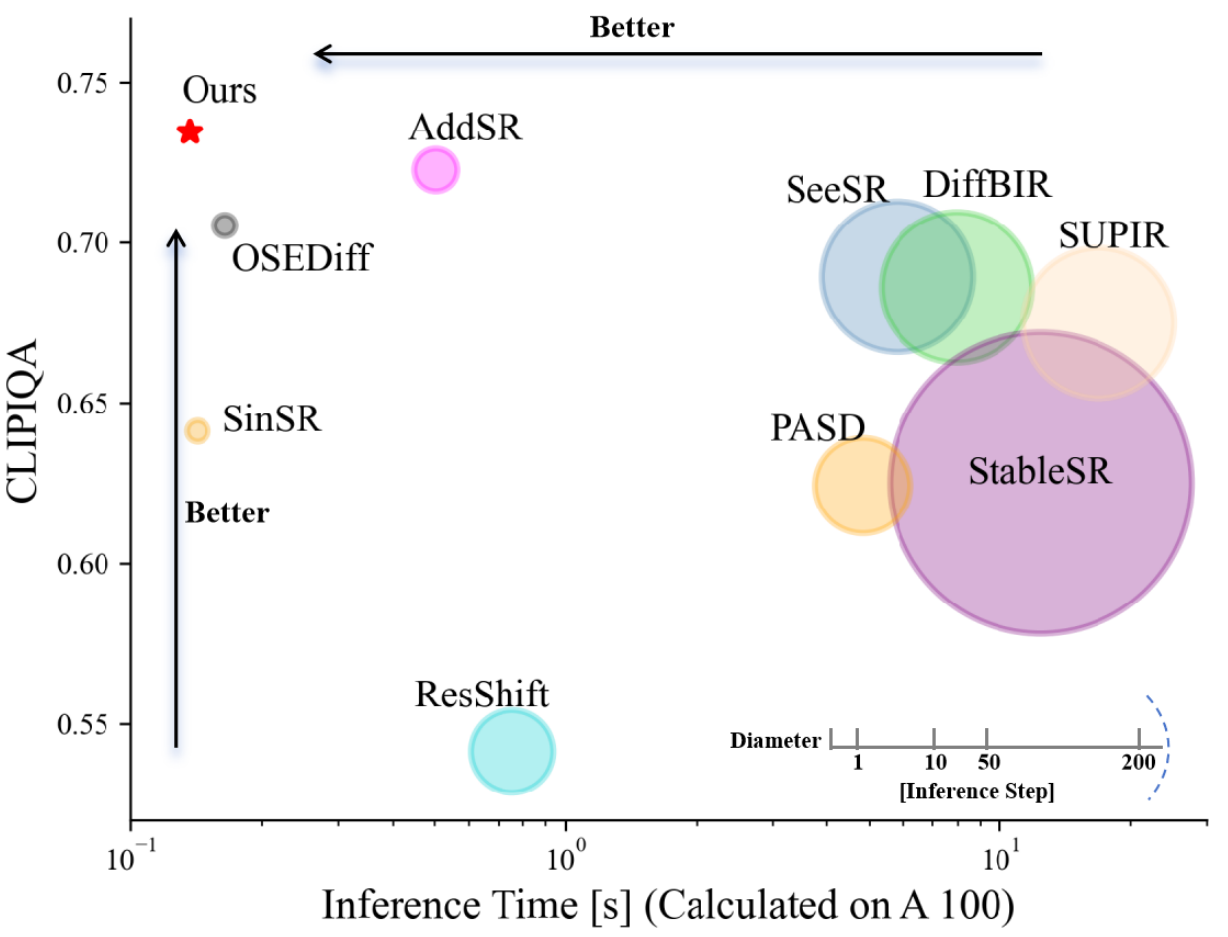
TSD-SR: One-Step Diffusion with Target Score Distillation for Real-World Image Super-Resolution
Linwei Dong*, Qingnan Fan*, Yihong Guo, Zhonghao Wang, Qi Zhang, Jinwei Chen, Yawei Luo, Changqing Zou.
- The first image super-resolution work that leverages the pretrained diffusion transformer (DIT) prior, specifically Stable Diffusion 3.
- TSD-SR has superior restoration results (most of the metrics perform the best) and the fastest inference speed (e.g. 40 times faster than SeeSR) compared to the past Real-ISR approaches based on pre-trained diffusion priors.

Text-Aware Real-World Image Super-Resolution via Diffusion Model with Joint Segmentation Decoders
Qiming Hu, Linlong Fan, Yiyan Luo, Yuhang Yu, Xiaojie Guo, Qingnan Fan.
- The first full-image text super-resolution work utilizing the diffusion priors.
- A novel diffusion-based SR framework, which integrates text-aware attention and joint segmentation decoders to recover not only natural details but also the structural fidelity of text regions in degraded real-world images.

Generating Manga from Illustrations via Mimicking Manga Creation Workflow
Lvmin Zhang, Xinrui Wang, Qingnan Fan, Yi Ji, ChunPing Liu.
- A data-driven framework to convert a digital illustration into three corresponding components: manga line drawing, regular screentone, and irregular screen texture. These components can be directly composed into manga images and can be further retouched for more plentiful manga creations.

A General Decoupled Learning Framework for Parameterized Image Operators
Qingnan Fan*, Dongdong Chen*, Lu Yuan, Gang Hua, Nenghai Yu, Baoquan Chen.
- A journal extension of our ECCV 2018 paper. We further propose a cheap parameter-tuning version of the decouple learning framework that enables real-time alternation between different image operators.

Image Smoothing via Unsupervised Learning
Qingnan Fan, Jiaolong Yang, David Wipf, Baoquan Chen, Xin Tong.
arXiv / codes / supp file / bibtex
- Treat deep learning as an optimization tool to minimize the proposed image smoothing objective function in an unsupervised manner. Multiple different smoothing effects can be easily learned by adaptively changing the proposed objective function.
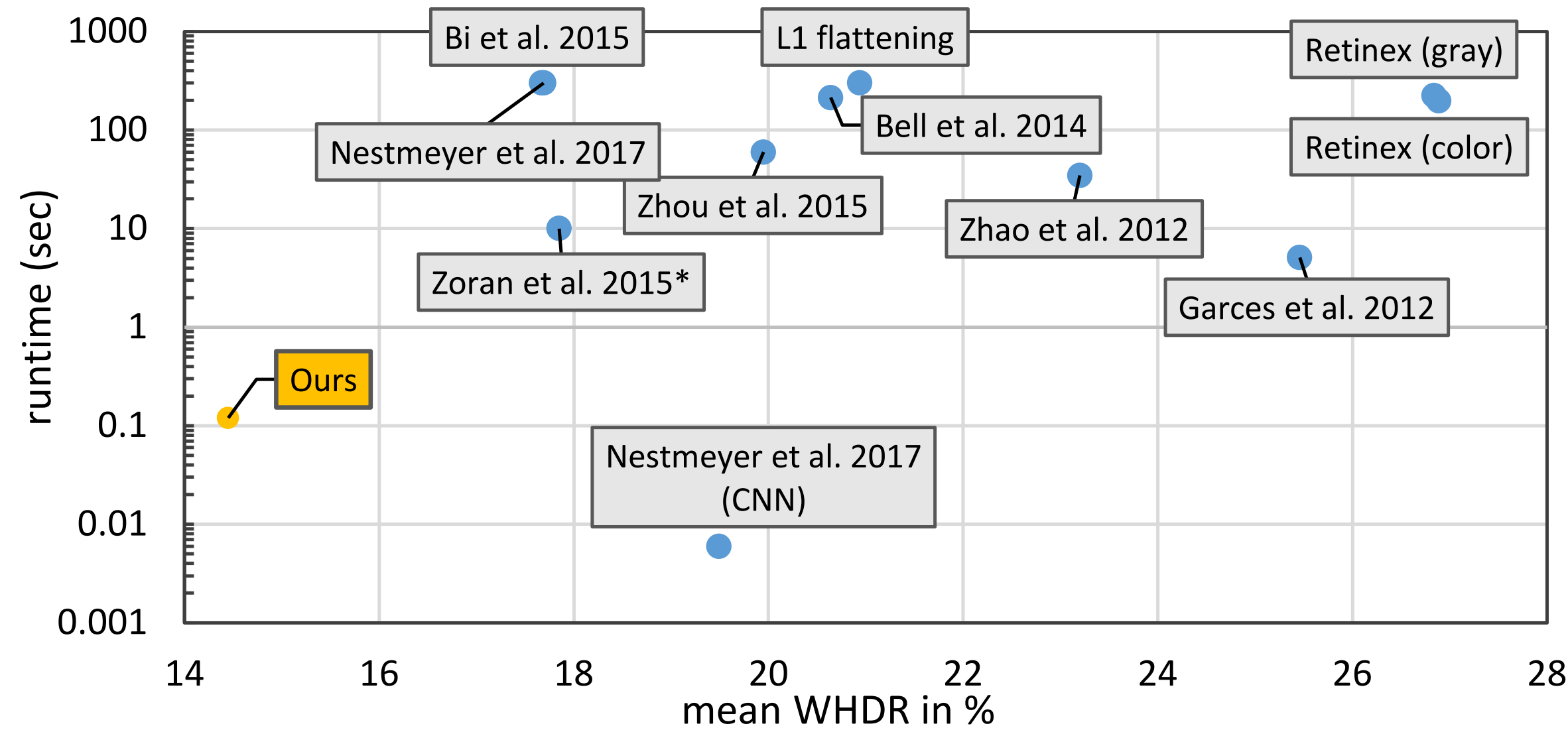
Revisiting Deep Intrinsic Image Decompositions
Qingnan Fan, Jiaolong Yang, Gang Hua, Baoquan Chen, David Wipf.
arXiv / codes / slides / supp file / poster / bibtex
- The first demonstration of a single basic deep architecture capable of achieving state-of-the-art results when applied to each of the major intrinsic benchmarks.

A Generic Deep Architecture for Single Image Reflection Removal and Image Smoothing
Qingnan Fan, Jiaolong Yang, Gang Hua, Baoquan Chen, David Wipf.
arXiv / codes / supp file / poster / bibtex
- An advanced deep architecture for low-level vision tasks; A novel reflection image synthesis approach which enables outstanding generalization ability to real images with trained newtork.

JumpCut: Non-Successive Mask Transfer and Interpolation for Video Cutout
Qingnan Fan, Fan Zhong, Dani Lischinski, Daniel Cohen-Or, Baoquan Chen.
codes / slides / video / supp file / dataset / bibtex
- An interactive real-time video segmentation algorithm. Significantly improve the video cutout accuracy and efficiency.
📚 Embodied AI

SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
Yuzheng Liu*, Siyan Dong*, Shuzhe Wang, Yingda Yin, Yanchao Yang, Qingnan Fan, Baoquan Chen.
- Award: China3DV 2025, Top1 paper.
- SLAM3R is a real-time dense scene reconstruction system that regresses 3D points from video frames using feed-forward neural networks, without explicitly estimating camera parameters.
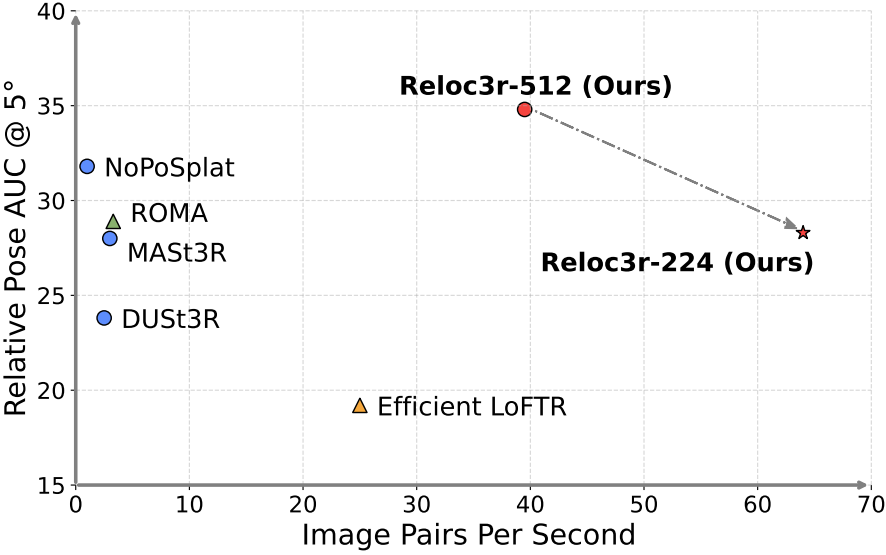
Siyan Dong*, Shuzhe Wang*, Shaohui Liu, Lulu Cai, Qingnan Fan, Juho Kannala, Yanchao Yang.
arXiv / video / demo (online) / codes
- Reloc3r is a simple yet effective camera pose estimation framework that combines a pre-trained two-view relative camera pose regression network with a multi-view motion averaging module.

Scene-aware Activity Program Generation with Language Guidance
Zejia Su, Qingnan Fan, Xuelin Chen, Oliver van Kaick, Hui Huang, Ruizhen Hu.
project page / supp file / bibtex
- We address the problem of scene-aware activity program generation, which requires decomposing a given activity task into instructions that can be sequentially performed within a target scene to complete the activity.
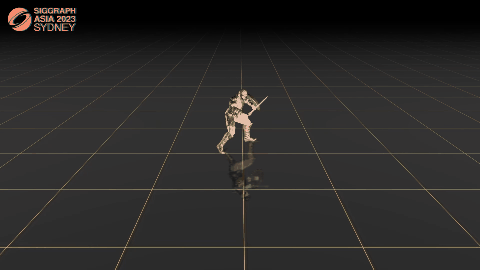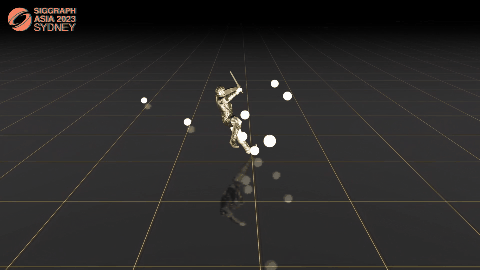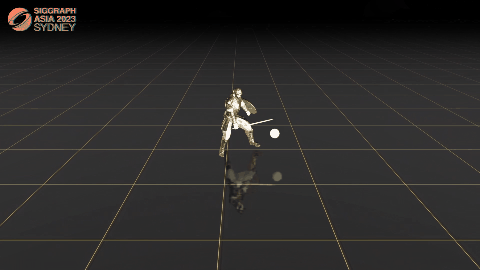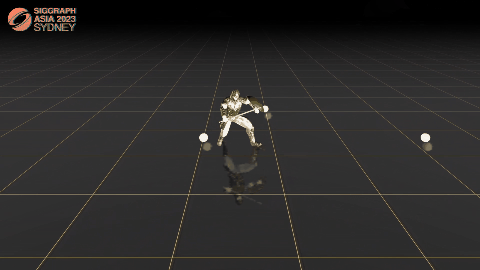
C·ASE: Learning Conditional Adversarial Skill Embeddings for Physics-based Characters
Zhiyang Dou, Xuelin Chen, Qingnan Fan, Taku Komura, Wenping Wang.
arXiv / project page / video / bibtex
- We present C·ASE, an efficient and effective framework that learns conditional Adversarial Skill Embeddings for Elite physics-based characters.

DualAfford: Learning Collaborative Visual Affordance for Dual-gripper Object Manipulation
Yan Zhao*, Ruihai Wu*, Zhehuan Chen, Yourong Zhang, Qingnan Fan, Kaichun Mo, Hao Dong.
arXiv / project page / video / bibtex
- We propose a novel learning framework, DualAfford, to learn collaborative affordance for dual-gripper manipulation tasks. The core design of the approach is to reduce the quadratic problem for two grippers into two disentangled yet interconnected subtasks for efficient learning.
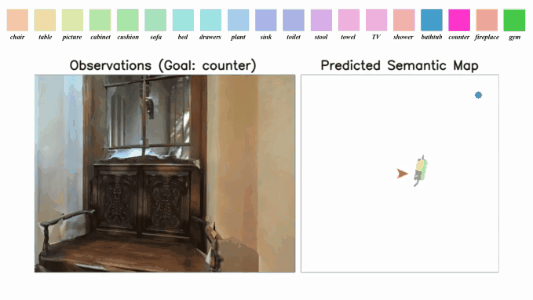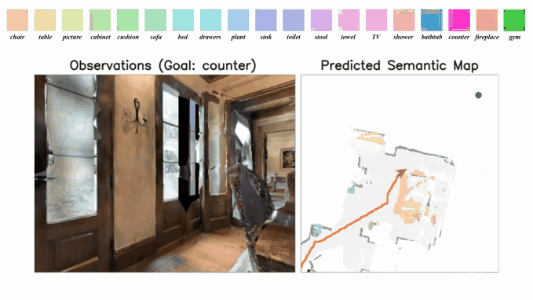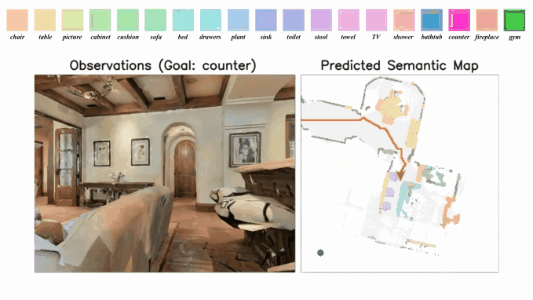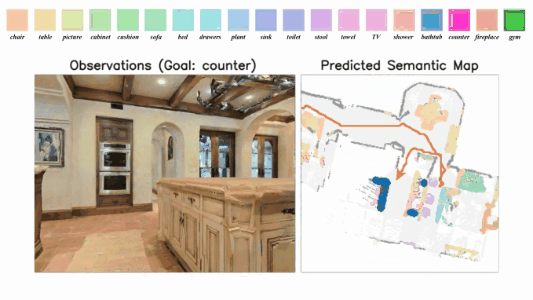
3D-Aware Object Goal Navigation via Simultaneous Exploration and Identification
Jiazhao Zhang*, Liu Dai*, Fanpeng Meng, Qingnan Fan, Xuelin Chen, Kai Xu, He Wang.
arXiv / project page / bibtex
- We propose a framework for the challenging 3D-aware Object goal navigation task based on two straightforward sub-policies. The two sub-polices, namely corner-guided exploration policy and category-aware identification policy, simultaneously perform by utilizing online fused 3D points as observation.

VAT-Mart: Learning Visual Action Trajectory Proposals for Manipulating 3D ARTiculated Objects
Ruihai Wu*, Yan Zhao*, Kaichun Mo*, Zizheng Guo, Yian Wang, Tianhao Wu, Qingnan Fan, Xuelin Chen, Leonidas Guibas, Hao Dong.
arXiv / project page / codes / video / bibtex
- Award: WAIC 2025, Young Outstanding Paper Award
- We design an interaction-for-perception framework, VAT-MART, to learn actionable visual representations for more effective manipulation of 3D articulated objects.

Yian Wang*, Ruihai Wu*, Kaichun Mo*, Jiaqi Ke, Qingnan Fan, Leonidas Guibas, Hao Dong.
arXiv / project page / codes / video / bibtex
- In this paper, we propose a novel framework, named AdaAfford, that learns to perform very few test-time interactions for quickly adapting the affordance priors to more accurate instance-specific posteriors.
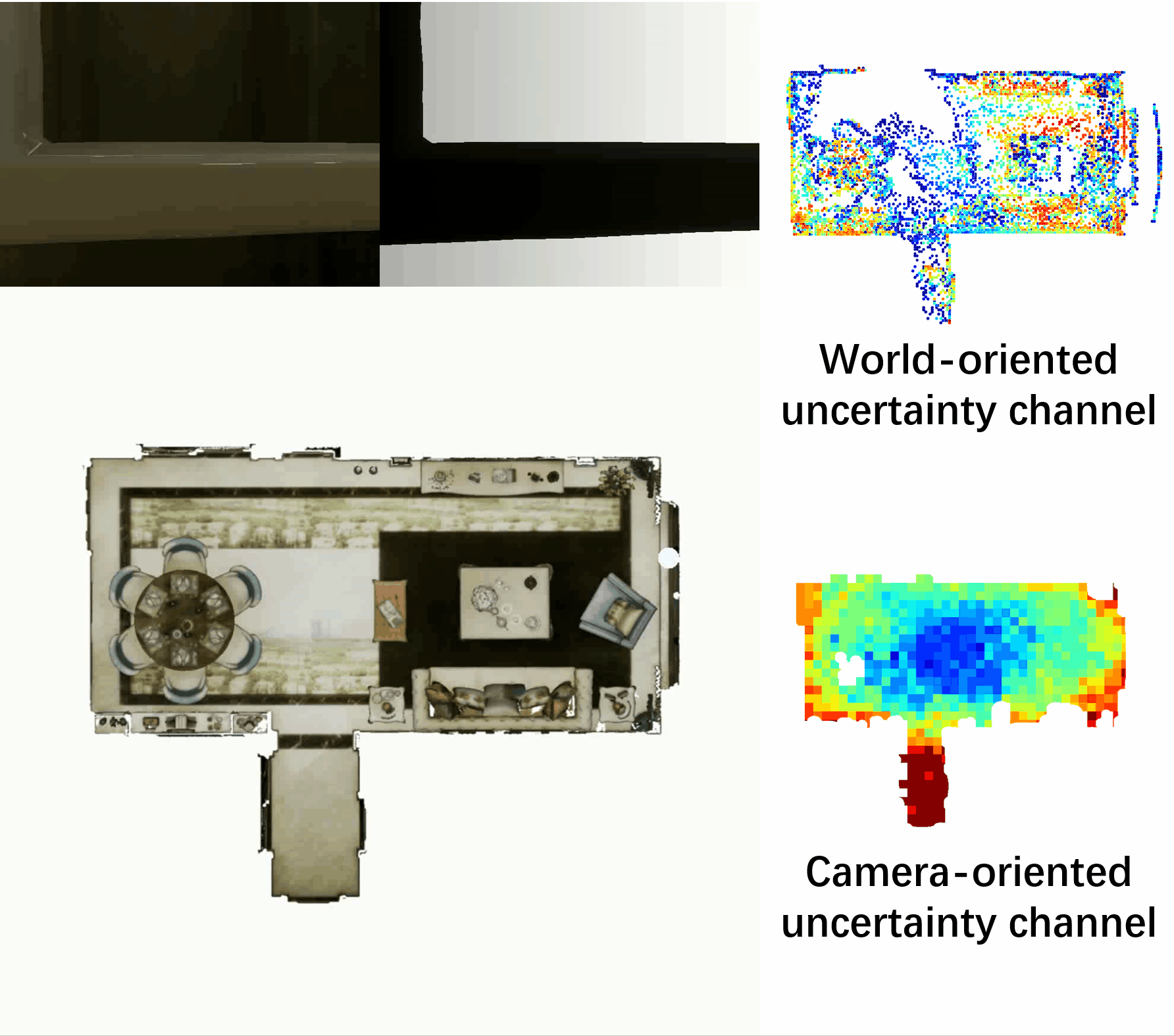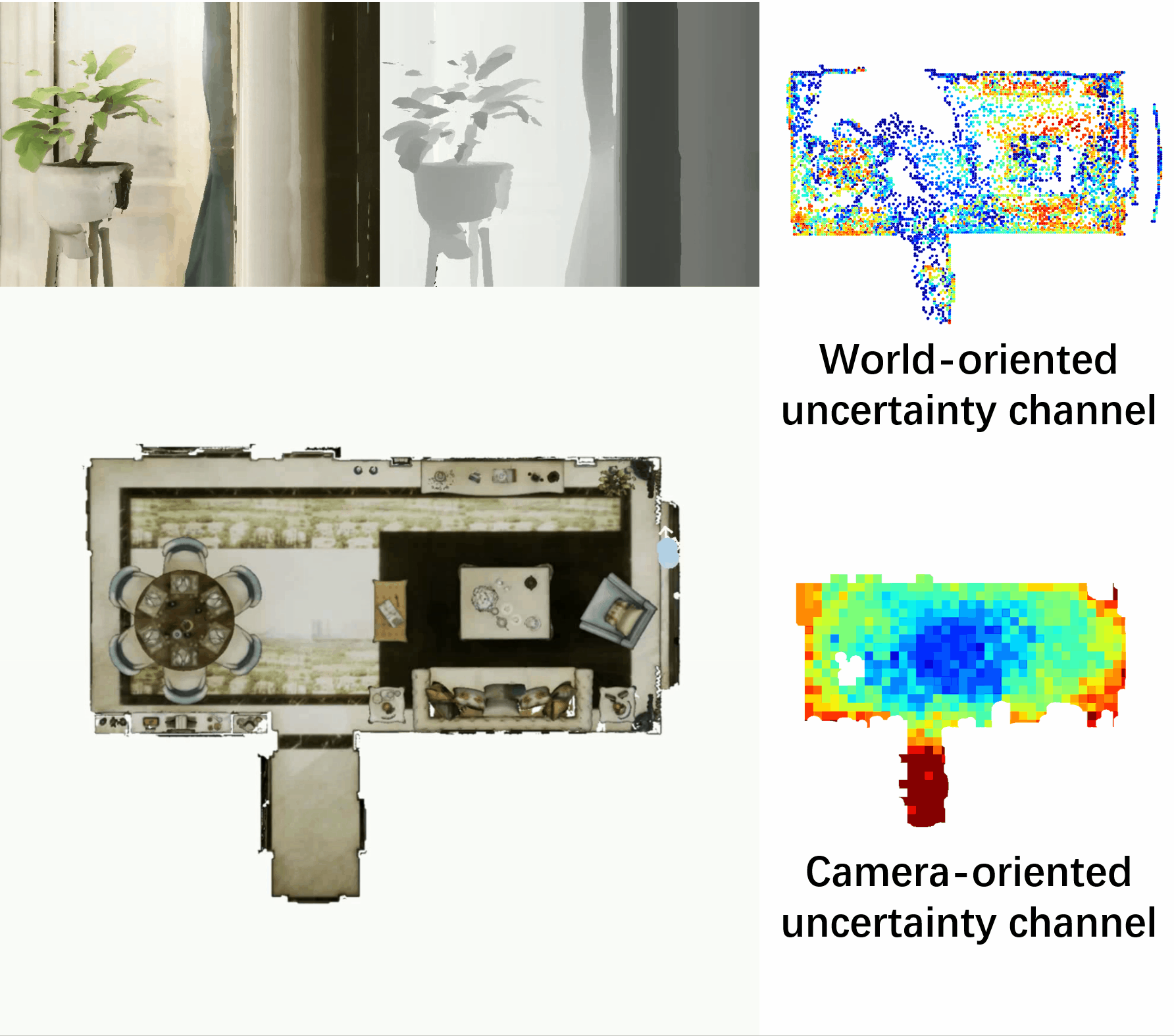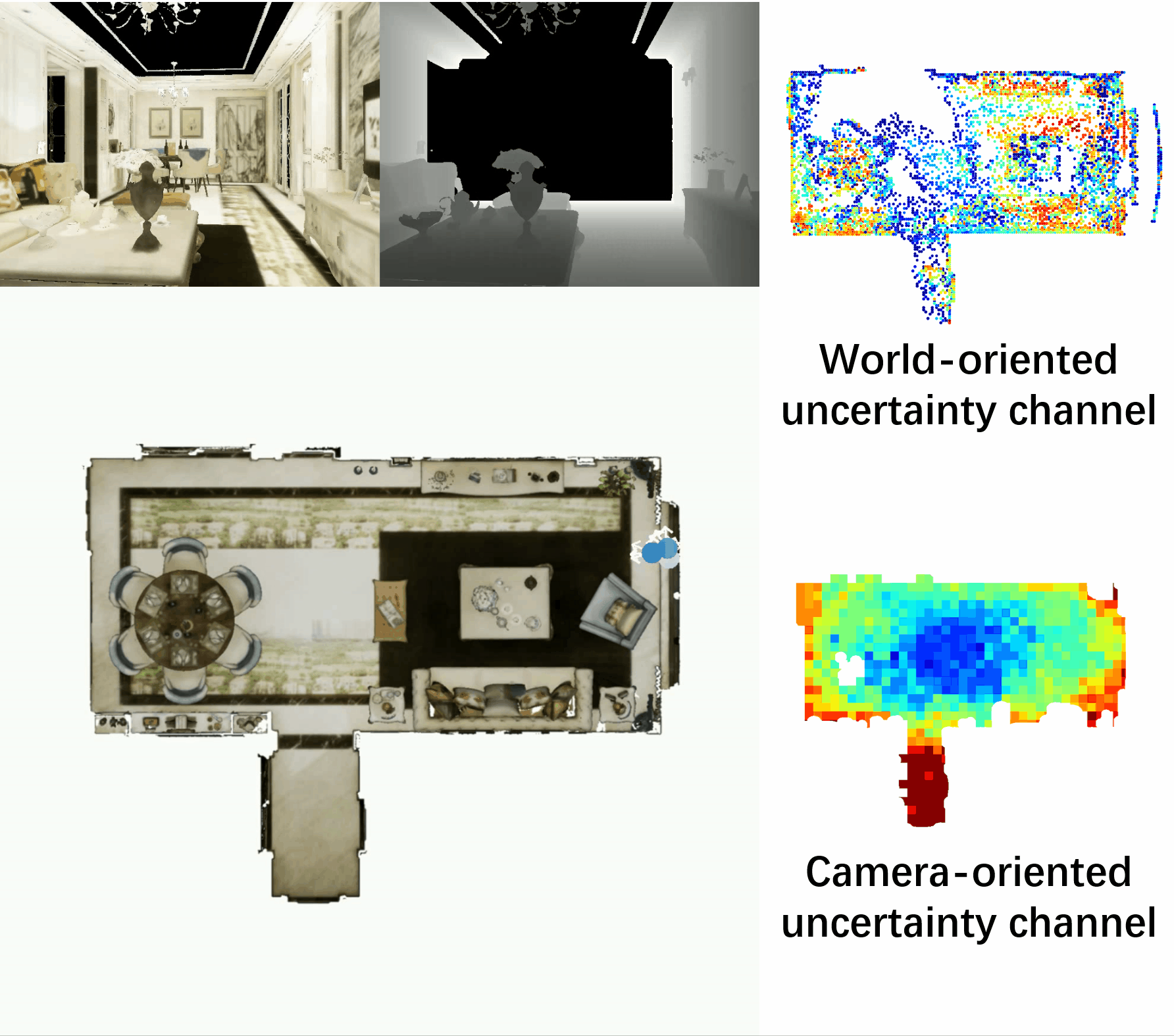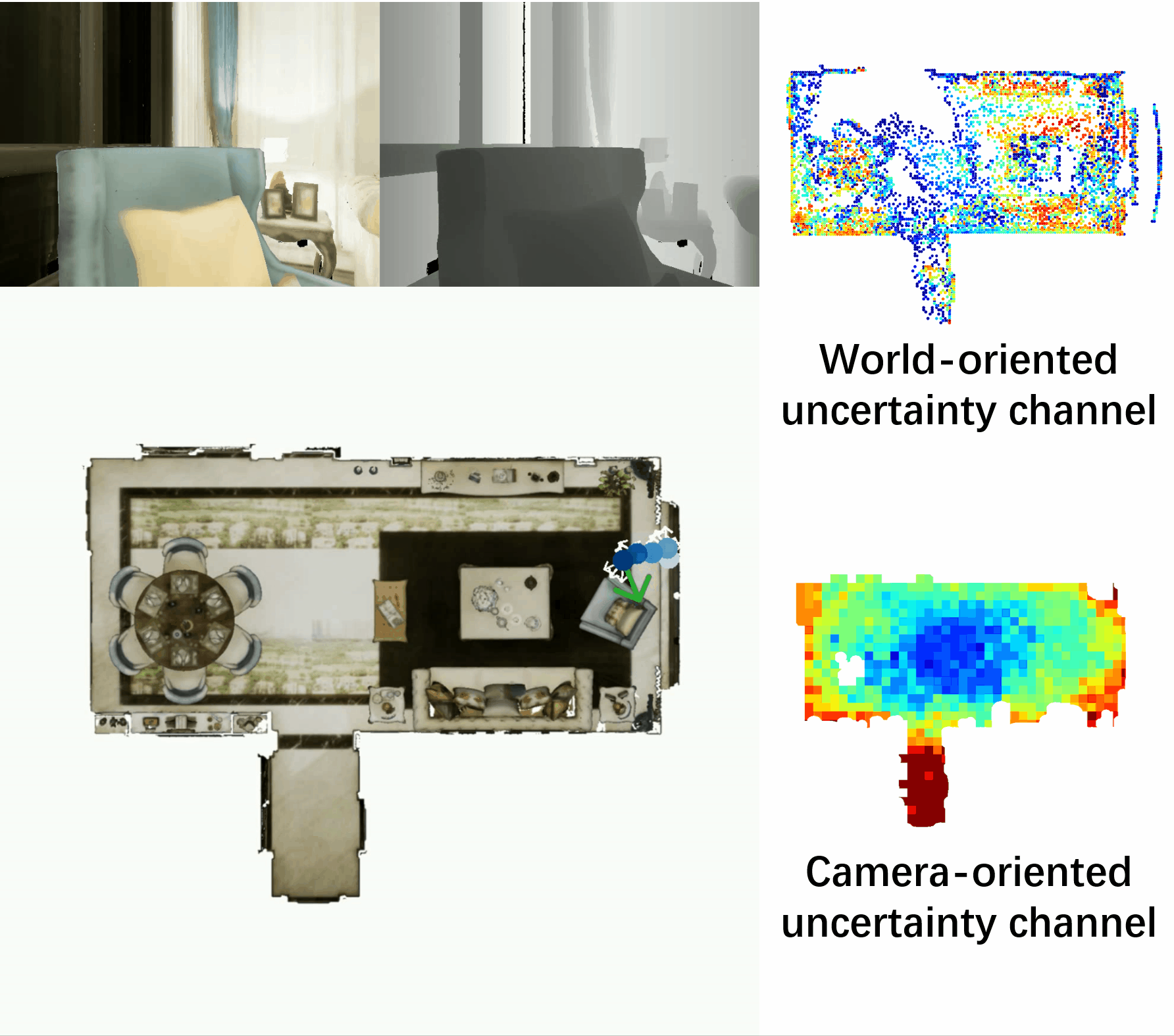
Towards Accurate Active Camera Localization
Qihang Fang*, Yingda Yin*, Qingnan Fan, Fei Xia, Siyan Dong, Sheng Wang, Jue Wang, Leonidas Guibas, Baoquan Chen.
arXiv / codes / video / supp file / bibtex
- In this work, we explicitly model the camera and scene uncertainty components to solve the problem of active camera localization by reinforcement learning. Our algorithm improves over the state-of-the-art Markov Localization based approaches by a large margin on the fine-scale camera pose accuracy.

Multi-Robot Active Mapping via Neural Bipartite Graph Matching
Kai Ye*, Siyan Dong*, Qingnan Fan, He Wang, Li Yi, Fei Xia, Jue Wang, Baoquan Chen.
arXiv / codes / video / supp file / poster / bibtex
- We propose a novel multi-robot active mapping algorithm by reducing the problem to bipartite graph matching, solved by the proposed multiplex graph neural network (mGNN) via reinforcement learning.

CAPTRA: CAtegory-level Pose Tracking for Rigid and Articulated Objects from Point Clouds
Yijia Weng*, He Wang*, Qiang Zhou, Yuzhe Qin, Yueqi Duan, Qingnan Fan, Baoquan Chen, Hao Su, Leonidas Guibas.
arXiv / project page / codes / video / bibtex
- For the first time, we propose a unified framework that can handle 9-DoF pose tracking for novel rigid object instances as well as per-part pose tracking for 3D articulated objects.
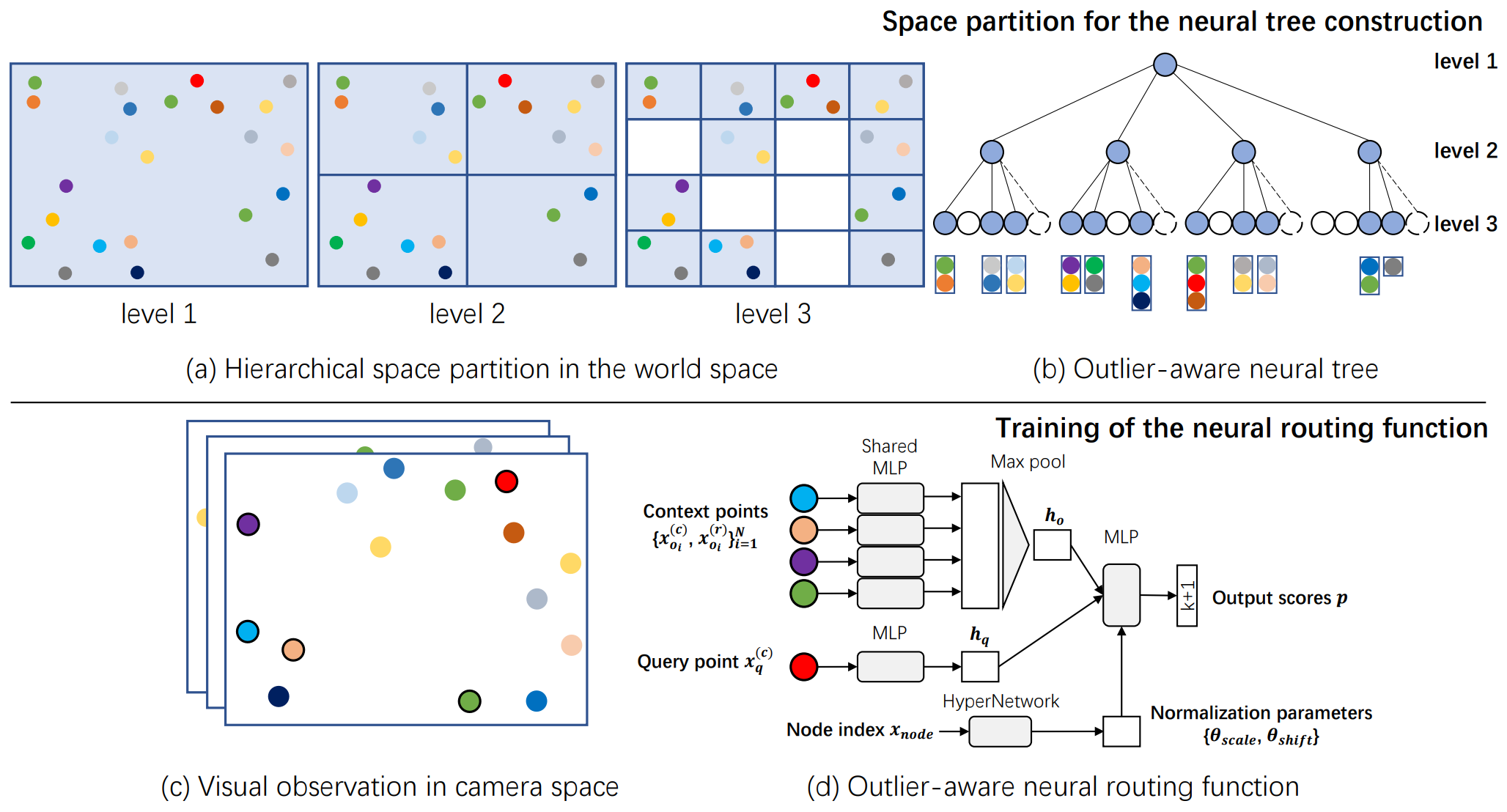
Siyan Dong*, Qingnan Fan*, He Wang, Ji Shi, Li Yi, Thomas Funkhouser, Baoquan Chen, Leonidas Guibas.
arXiv / codes / video / bibtex
- A novel outlier-aware neural tree to tackle the camera localization challenges in dynamic indoor environments. It achieves the best performance in the RIO-10 benchmark.
🎖 Honors and Awards
- 2022, Tencent Outstanding Contributor
- 2020, CCF Doctorial Dissertation Award Nominee (CCF 优博提名)
- 2018, Academic Star Nominee of Shandong University (10/20000)
- 2015, Presidential Scholarship of Shandong University (35/20000) (Highest honor for students in SDU, only 35 elected among around 20000 candidates)
📖 Educations
- 2019.09 - 2021.03, PostDoc, Stanford University
- 2014.09 - 2019.06, Ph.D., Shandong University
- 2010.09 - 2014.06, Undergraduate, Shandong University
💬 Invited Talks
- 2022.04, Active 3D scene understanding and its applications, “三维视觉与智能图形”前沿论坛, 图图名师讲堂
- 2021.10, Visual Localization, Embodied AI Workshop, Valse
- 2019.01, Deep Learning in Computational Photography, USC ICT/UW Reality Lab/Berkeley/Stanford/Google/MSR
- 2018.12, Deep Learning for Single Image Artifact Removal, ACCV Tutorial
- 2018.12, Image Smoothing via Unsupervised Learning, GAMES Webinar
- 2018.08, Discovering Unsupervised Learning in Image Processing, CIA, Cambridge University
💻 Internships and Visiting students
- 2018.04 - 2019.08, Beijing Film Academy, China.
- 2018.08 - 2018.10, University of Cambridge, UK.
- 2016.09 - 2018.03, Microsoft Research Asia, China.
- 2015.04 - 2015.05, Tel Aviv University, Israel.
- 2014.10 - 2014.11, The Hebrew University of Jerusalem, Israel.